4 Evaluations
4.1 The Evolution of Model Evaluation
Assessing modern general-purpose model (GPM)s is challenging due to their broad applicability across diverse domains. Unlike specialized machine learning (ML) models, which are designed for specific tasks and can be directly tested on well-defined objectives [Raschka (2018)], it is impractical to evaluate GPMs on every possible capability. As a result, many evaluations rely on structured benchmarks that measure proficiency in key areas such as mathematics, chemistry, and language understanding [Tikhonov and Yamshchikov (2023)]. However, such benchmarks often fall short in capturing open-ended problem-solving or emergent abilities that arise without explicit training for them and are sensitive to factors such as prompt phrasing and task framing [Siska et al. (2024); Andriushchenko et al. (2024)].
Early benchmarks primarily focused on evaluating specialized models based on their ability to predict molecular properties from molecular structures. [Wu et al. (2018)] While useful, these evaluations largely emphasized numerical accuracy on the isolated tasks the models were fine-tuned on, without probing the more complex reasoning or generative capabilities that GPMs aim to capture. Over time, this evolution expanded to exam-like problem-solving, assessing structured tasks similar to those found in academic chemistry courses. [Zaki et al. (2023); Li et al. (2023)] More recent efforts aim to evaluate a broader range of skills, including knowledge retrieval, logical reasoning, and even the ability to mimic human intuition when solving complex chemical problems.[Feng et al. (2024); Mirza et al. (2025)] This shift highlights the need for more flexible evaluation methods that consider the specific context and nature of each task. Rather than relying solely on static benchmarks, there is a growing demand for assessments that dynamically account for the diversity of chemical tasks and the specific capabilities required to solve them—mirroring the multifaceted potential of GPMs in chemistry. At the same time, the broadened scope of evaluation introduces additional choices about what and how to measure, which increases complexity. In the following section, we therefore discuss some of the most important of these choices in more detail. Table 4.1 gives an overview of some benchmarks that have been used in the chemical sciences.
| Benchmark name | Overall topic | Curation method | Approx. count |
|---|---|---|---|
| CAMEL - Chemistry [Li et al. (2023)] | General Chemistry multiple-choice question (MCQ) | A, L | 20 K |
| ChemBench [Mirza et al. (2025)] | General Chemistry MCQ, Reasoning | M | 2.7 K |
| ChemIQ [Runcie, Deane, and Imrie (2025)] | Molecule Naming, Reasoning, Reaction Generation, Spectrum Interpretation | A | 796 |
| ChemLLM [Zhang et al. (2024)] | Molecule Naming, Property Prediction, Reaction Prediction, Reaction Conditions Prediction, Molecule & Reaction Generation, Molecule Description | A, L | 4.1 K |
| ChemLLMBench [T. Guo et al. (2023)] | Molecule Naming, Property Prediction, Reaction Prediction, Reaction Conditions Prediction, Molecule & Reaction Generation | A, L | 800 |
| LAB-Bench [Laurent et al. (2024)] | Information Extraction, Reasoning, Molecule & Reaction Generation | A, M | 2.5 K |
| LabSafety Bench [Zhou et al. (2024)] | Lab Safety, Experimental Chemistry | M, L | 765 |
| LlaSMol [Yu et al. (2024)] | Molecule Naming, Property Prediction, Reaction Prediction, Reaction Conditions Prediction, Molecule & Reaction Generation, Molecule Description | A, L | 3.3 M |
| MaCBench [Alampara et al. (2025)] | Multimodal Chemistry, Information Extraction, Experimental Chemistry, Material Properties & Characterization | M | 1.2 K |
| MaScQA [Zaki et al. (2023)] | Material Properties & Characterization, Reasoning, Experimental Chemistry | A | 650 |
| MolLangBench [F. Cai et al. (2025)] | Molecule Structure Understanding, Molecule Generation | A, M | 4 K |
| MolPuzzle [K. Guo et al. (2024)] | Molecule Understanding, Spectrum Interpretation, Molecule construction | A, L, M | 23 K |
| SciAssess [H. Cai et al. (2024)] | General Chemistry MCQ, Information Extraction, Reasoning | A, M | 2 K |
| SciKnowEval [Feng et al. (2024)] | General Chemistry MCQ, Information Extraction, Reasoning, Lab Safety, Experimental Chemistry | A, L | 18.3 K |
Abbreviations: A: Automated methods, L: Usage of LLMs, M: Manual curation.
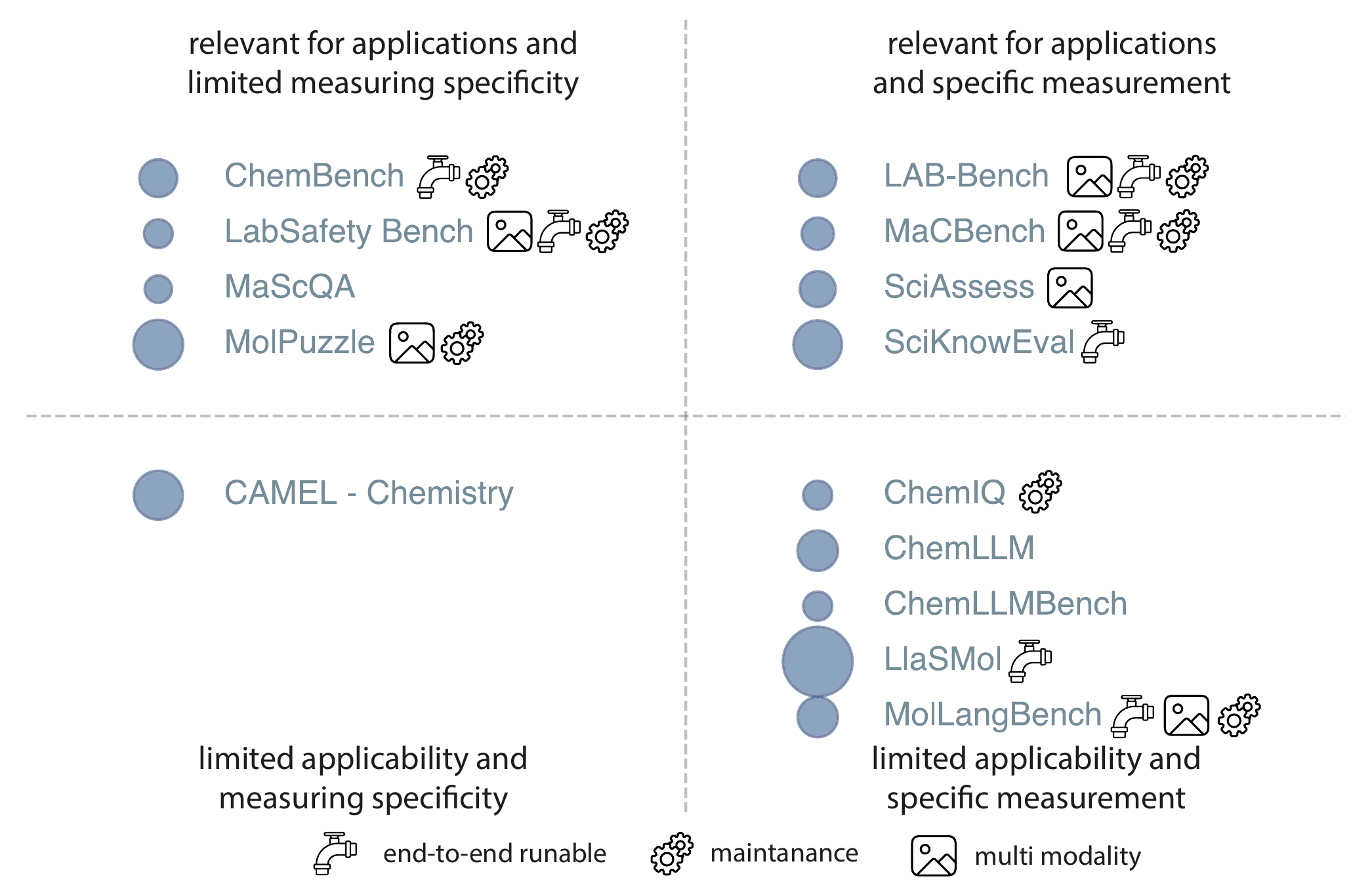
4.2 Design of Evaluations
4.2.1 Desired Properties for Evaluations
To meaningfully evaluate GPMs, we must first consider what makes a good evaluation. Ideally, an evaluation should provide insights that translate into real-world impact, allowing comparisons between models. Thus, evaluation results must be stable over time and reproducible across different environments—assuming access to the same model weights or version, which is not always guaranteed when using proprietary application programming interface (API)s. [Ollion et al. (2024)] A key challenge is so-called construct validity—ensuring that evaluations measure what truly matters rather than what is easiest to quantify. For example, asking a model to generate valid simplified molecular input line entry system (SMILES) strings may test surface-level structure learning but fails to assess whether the model understands chemical reactivity or synthesis planning. Many methods fall into the trap of assessing proxy tasks instead of meaningful competencies, which leads to misleading reports of progress. However, it is important to note that proxy tasks are often chosen because measurements at higher fidelity are more expensive or time-consuming to construct.
4.2.1.1 Data and Biases
The choice of what and how to measure is highly impacted by the data. Datasets in chemistry often differ in subtle but impactful ways: biases in chemical space coverage (e.g., overrepresented reaction types) [Jia et al. (2019); Fujinuma et al. (2022)], variations in data fidelity (e.g., density functional theory (DFT) vs. experimental measurements), inconsistent underlying assumptions (e.g., simulation level or experimental conditions), and differences in task difficulty. These differences can distort what evaluations actually measure, making comparisons across models or tasks unreliable. [Peng et al. (2024)] Moreover, the process of collecting or curating data itself introduces further variability, introduced by incomplete or biased coverage of the chemical space, computational constraints, or design decisions in the construction of tasks. As such, evaluations must be built using transparent, well-documented construction protocols, with clearly stated scope and limitations.
4.2.1.2 Scoring Mechanism
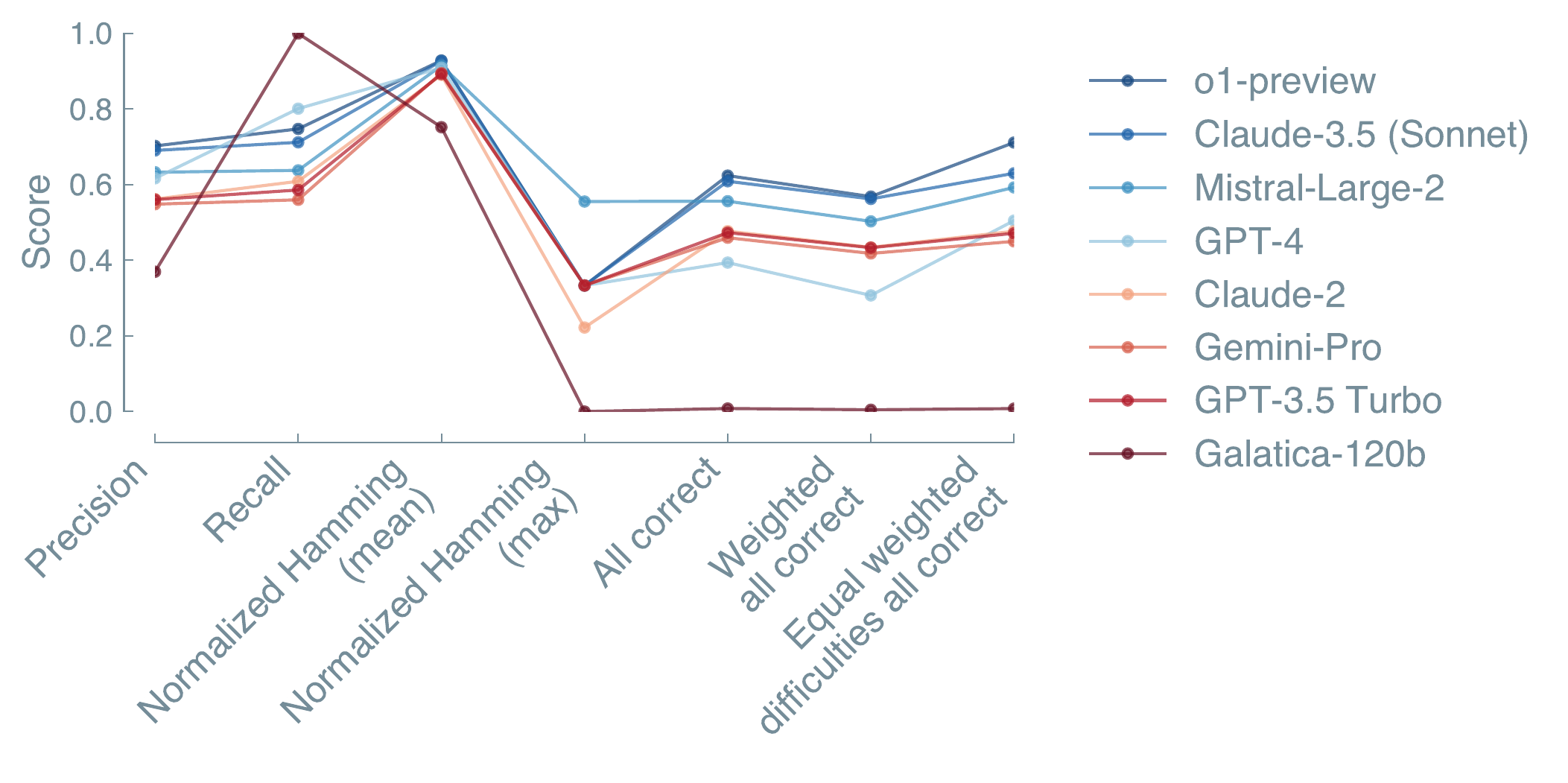
ChemBench (Mirza et al. 2025) rankings based on different scoring metrics: All metrics are a sum, weighted sum, or maximum values over all MCQs. The weighted sums are calculated by taking the manually rated difficulty (basic, immediate, advanced) of the question into account. For equal weighting, all categories are weighted equally, regardless of the number of questions. The metric “all correct” is a binary metric indicating if a given answer is completely correct. For normalized Hamming (max), the normalized maximum value of the Hamming loss of each model was taken. We find that the ranking of models changes if we change the metric, or even just the aggregation—showcasing the importance of proper and transparent evaluation design.
The way model performance is scored has a direct impact on how results are interpreted and compared. Leaderboards and summary statistics often shape which models are considered state-of-the-art, making even small design choices in scoring, such as metric selection, aggregation, or treatment of uncertainty, highly consequential (see Figure 4.2). Inconsistent or poorly designed scoring can lead to misleading conclusions or unfair comparisons. For example, in tasks where multiple correct answers are possible, different evaluation strategies yield different insights: a permissive metric may assign partial credit for each correct option selected, while a stricter “all-or-nothing” metric only gives credit if the full set of correct choices is identified without any mistakes. The former captures varying levels of performance, while the latter enforces a binary pass or fail threshold. Aggregation strategies, such as task averaging or difficulty-based weighting, further influence the overall score and can substantially shift model rankings.
4.2.1.3 Statistical significance and uncertainty estimation
Statistical significance and uncertainty estimation are essential for drawing robust conclusions. Evaluations must include a sufficient number of questions per task type to ensure statistical power, and repeated runs (e.g., different seeds or sampling variations) are needed to report confidence intervals or error bars. [Tikhonov and Yamshchikov (2023)] While this is feasible for automated, large-scale benchmarks, it becomes significantly more challenging in resource-intensive settings such as real-world deployment studies (e.g., testing a model in a wet-lab setting), where replicability and scale are limited.
4.2.1.4 Reproducibility and Reporting
Without clear and consistent documentation, even well-designed evaluations risk being misunderstood or unreproducible. To ensure that results are interpretable, verifiable, and extensible, every step of the evaluation process should be clearly specified, from prompt formulation and data pre-processing to metric selection and aggregation. Standardized evaluation protocols, careful tracking of environmental variables (e.g., hardware, model version, and sampling settings such as the inference temperature for LLMs), and consistent version control (documenting the exact version of the used model) are essential to avoid unintentional variation across runs. Additionally, communicating limitations and design decisions openly can help the broader community understand the scope and reliability of the reported results. Alampara, Schilling-Wilhelmi, and Jablonka (2025) proposed evaluation cards as a structured format to transparently report all relevant details of an evaluation, including design choices, assumptions, and known limitations, making it easier for others to interpret, reproduce, and build upon the results. See example Note 4.1 for some of the best practices while building benchmarks.
Setup and Reporting
- Ensure full reproducibility: document all steps from data preparation to scoring.
- Fix and report: model checkpoint or API version, date and time, inference settings (e.g., temperature, context length).
- Store all evaluation assets (prompts, datasets, scripts) under version control for traceability.
- Clearly define: evaluation goal, task scope, data origin, and underlying assumptions.
Validation and Sanity Checks
- Check for potential training data leakage by testing partial completions or measuring accuracy drop under paraphrasing [Duarte et al. (2024)].
- Use clear-cut factual questions phrased in multiple ways to test consistency.
- Include prompts containing obvious errors (e.g., “benzene is not aromatic”) to probe factual robustness.
- Perform repeated runs with different random seeds or sampling temperatures to estimate uncertainty.
Bias and Construct Validity
- Verify that tasks measure intended skills (reasoning vs. recall).
- Balance question difficulty; include control and counterfactual items.
- Check dataset composition for chemical space or label bias.
Publication and Communication
- Double-check factual claims against trusted references.
- Report both metrics and qualitative error patterns.
- Use structured evaluation cards [Alampara, Schilling-Wilhelmi, and Jablonka (2025)] for transparency.
4.3 Evaluation Methodologies
4.3.1 Representational vs. Pragmatic Evaluations
It is useful to think of evaluations in ML as living on a spectrum from representational to pragmatic. Representational evaluations focus on measuring concepts that exist in the real world. For instance, one might ask how well a model predicts a physically significant quantity like the band gap of a material or the yield of a chemical reaction. In contrast, in pragmatic evaluations, the concept we measure is defined by the evaluation procedure itself. A well-known example of this is IQ tests. The IQ is not a physical property that exists in the world independent of the test. It is rather defined by the measurement procedure. In the practice of evaluating ML models, this includes tasks like answering MCQ or completing structured benchmarks, where meaning emerges primarily through performance comparison. Such evaluations are essential for standardization and progress tracking; however, they risk creating feedback loops, as models may end up optimized for benchmark success rather than real-world usefulness, thereby reinforcing narrow objectives or biases.[Alampara, Schilling-Wilhelmi, and Jablonka (2025); Skalse et al. (2022)]
4.3.1.1 Estimator Types
To systematically evaluate GPMs, various methods (so-called estimators) have been developed, yet their application in chemistry remains limited. Broadly, these approaches can be categorized into traditional benchmarks, challenges and competitions, red teaming and capability discovery, real-world deployment studies, ablation studies, and systematic testing. Each evaluation method has its own strengths and limitations, and no single approach can comprehensively capture a model’s performance across all potential application scenarios.
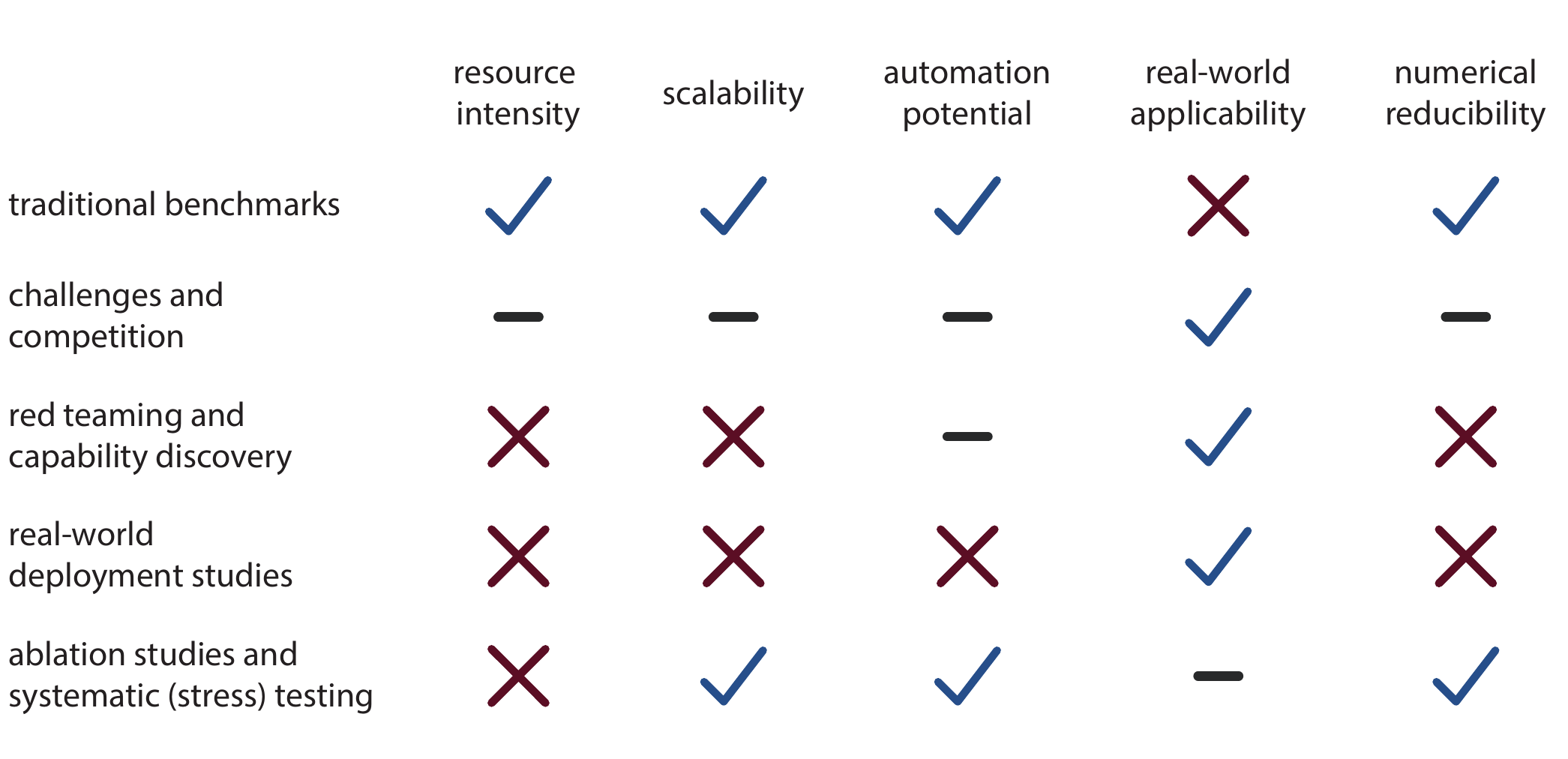
4.3.1.2 Traditional Benchmarks
Traditional benchmarks can provide a fast and scalable evaluation of the models. In the context of ML, a benchmark typically refers to a curated collection of tasks or questions alongside a defined evaluation protocol, which allows different models to be compared under the same conditions. Despite their advantages, summarized in Figure 4.3, benchmarks come with limitations. They often struggle to capture real-world impact, as they evaluate models in controlled environments that may not reflect the complexity and open-endedness of real-world applications. Current chemistry benchmarks like ChemBench[Mirza et al. (2025)] and CAMEL - Chemistry[Li et al. (2023)] mostly fall on the pragmatic side of the measurement spectrum, as they are designed for comparison and decision-making rather than assessing inherent model properties. Classical benchmarks such as MoleculeNet [Wu et al. (2018)] typically target molecular properties—such as solubility or binding affinity—that are experimentally measurable and representationally grounded. However, their evaluation setup, which relies on static and narrowly defined datasets, often fails to capture real-world applicability.
An additional disadvantage of traditional benchmarks is ease of overfitting, where models are optimized for high scores rather than genuine improvements in real-world applications. This problem is closely linked to data leakage—also known as test set pollution—which refers to the unintentional incorporation of test set information into the training process. Such leakage can distort performance estimates, especially when models are trained on publicly available benchmarks.[Thompson (n.d.)] This exposure increases the risk that models learn to perform well on specific benchmark questions rather than developing a deeper, more generalizable understanding of the underlying concepts, leading to an overestimation of their true capabilities.
Several strategies have been proposed to mitigate these issues. One approach is to keep a portion of the benchmark private, preventing models from being exposed to evaluation data during training—as implemented in LAB-Bench, where \(20\%\) of the questions are held out to safeguard against data leakage and overfitting.[Laurent et al. (2024)] Alternatively, some initiatives explore privacy-preserving methods or the use of trusted third parties to evaluate models on held-out data without releasing it publicly. [EleutherAI (n.d.)] Another strategy is to regularly update benchmarks by introducing more difficult or diverse tasks over time. [Jimenez et al. (2023)] While this helps reduce overfitting by continually challenging models, it complicates long-term comparisons across versions and can undermine stability in performance tracking. [Alampara, Schilling-Wilhelmi, and Jablonka (2025)]
Another limitation is that most benchmarks force models to respond to every question, even when uncertain, preventing evaluation of their ability to recognize what they do not know—an essential skill in real-world settings. LAB-Bench addresses this by allowing models to abstain via an “insufficient information” option, enabling a more nuanced assessment that distinguishes between confident knowledge and uncertainty.
4.3.1.3 Challenges and Competitions
Competitions and challenges offer a structured way to evaluate models under realistic conditions, emphasizing prospective prediction and reducing overfitting risks.[Moult (2005)] Participants typically must submit predictions for a hidden test set, enabling blind, fair evaluation that more closely mirrors real-world deployment. Unlike standard benchmarking setups, these challenges often involve tasks with temporal, external, or domain-specific novelty, making them more resistant to subtle data leakage or overfitting through test set familiarity. While such challenges allow for systematic and rigorous assessment of model capabilities, they also require substantial coordination and oversight by a trusted third party.
Such challenges have been rare in chemistry to date, though recent examples in areas like polymer property prediction [Liu et al. (n.d.)] suggest this is beginning to change. More successful examples exist in related domains—most notably the critical assessment of techniques for protein structure prediction (CASP) competition[Moult (2005)] for protein structure prediction in biology, and the crystal structure prediction blind test challenge[Lommerse et al. (2000)] in materials science.
4.3.1.4 Red Teaming and Capability Discovery
Red teaming focuses on testing models in ways that they were not explicitly designed for, often probing their weaknesses, as well as unintended and unknown behaviors. [Perez et al. (2022); Ganguli et al. (2022)] This group of evaluations includes attempts to bypass alignment mechanisms through adversarial prompting—deliberate attempts to elicit harmful, unsafe, or hidden model outputs by manipulating the input in subtle ways—or to reveal unintended capabilities. [Zhu et al. (2023); Kumar et al. (2023)] Unlike standardized benchmarks, red teaming can reveal model abilities that remain undetected in evaluations with predefined tasks. However, a major challenge is the lack of systematic comparability. Results often depend on specific test strategies and are harder to quantify across models. Currently, most red teaming is conducted by human experts, making it a time-consuming process. Automated approaches are emerging to scale these evaluations [Ge et al. (2023)], but in domains like chemistry, effective automation requires models to possess deep scientific knowledge, which remains a significant challenge.
A concrete example of red teaming in chemistry was presented in the GPT-4 Technical Report [OpenAI et al. (2023)]. By augmenting GPT-4 with tools like molecule search, synthesis planning, literature retrieval, and purchasability checks, red-teamers were able to identify purchasable chemical analogs of a given compound, and even managed to have one delivered to a home address. While the demonstration used a benign leukemia drug, the same approach could, in principle, be applied to identify alternatives to harmful substances.[Urbina et al. (2022)]
4.3.1.5 Real-World Deployment Studies
Real-world deployment studies evaluate models in practical use settings, such as testing a GPM in a laboratory environment. Unlike controlled benchmarks, these studies provide insights into how models perform in dynamic, real-world conditions, capturing challenges that predefined evaluations may overlook. For example, a generative model might be used to suggest synthesis routes that are then tested experimentally, revealing failures due to overlooked side reactions or missing reaction feasibility. However, they come with significant drawbacks: they are highly time-consuming, and systematic comparisons between models are difficult, as real-world environments introduce variability that is hard to control.
To date, such evaluations remain rare in the chemical sciences.
4.3.1.6 Ablation Studies and Systematic Testing
Ablation studies analyze models by systematically isolating and testing individual components or capabilities. By removing or modifying specific parts of the models, the impact on performance can be evaluated, providing information on the model’s functionality and potential weaknesses. This approach can be relatively scalable and structured, allowing for thorough and reproducible assessments. Ablation studies reveal limitations and improve overall reliability by ensuring a deeper understanding of how different elements contribute to the model’s behavior.
Alampara et al. (2025) conducted ablation studies to isolate the effects of scientific terminology, task complexity, and prompt guidance on model performance in multimodal chemistry tasks. In MaCBench, they showed that removing scientific terms or adding explicit guidance substantially improved model accuracy, suggesting that current models often rely on shallow heuristics rather than deep understanding. These structured ablations highlight specific failure modes and inform targeted improvements in prompt design and training strategies.
4.4 Future Directions
4.4.1 Emerging Evaluations Needs
To evaluate GPMs in real-world conditions, more open-ended, multimodal, and robust approaches are needed. This is particularly evident in chemistry, where meaningful tasks often extend beyond text and require interpreting molecular structures, reaction schemes, or lab settings. Here, vision plays a fundamental role, enabling perception and reasoning in complex environments—such as reading labels, observing color changes, or manipulating an apparatus. [Eppel et al. (2020)] In addition to visual cues, auditory signals—such as timer alerts or mechanical noise—can play a critical role in ensuring safety and coordination in lab environments. Sensorimotor input may also be relevant for simulating or guiding physical manipulation tasks, such as pipetting, adjusting equipment, or following multistep experimental procedures.
Beyond multimodality, another crucial challenge lies in evaluating open-ended scientific capabilities. Unlike well-defined benchmarks with fixed answers, real-world scientific inquiry is inherently open-ended.[Mitchener et al. (2025)] This not only demands flexible and adaptive evaluation schemes but also raises deeper questions about what constitutes scientific understanding in generative models. This becomes even more important as agent-based systems Section 3.12 gain traction—models that do not simply respond to prompts but autonomously plan, reason, and execute multistep tasks in interaction with tools, databases, and lab environments. [Cao et al. (2024); Mandal et al. (2024)] Simple input-output benchmarks are insufficient; instead, we need frameworks that can track progress in dynamic, goal-driven settings, where multiple valid solutions may exist. [Nie et al. (2025)]
In parallel to capability assessments, the evaluation of safety (see Section 7.2 is becoming increasingly important—especially as GPMs gain access to sensitive scientific knowledge and tools.[Bran et al. (2024); Boiko et al. (2023)] Current safety evaluations often rely on manual red teaming Section 4.3, which is neither scalable nor systematic. Future evaluation frameworks must therefore include robust, automated, and scalable safety testing pipelines, capable of detecting misuse potential and risky behaviors across modalities and contexts.[Goldstein et al. (2023)]
Moreover, evaluations should not be limited to static benchmarks. One promising avenue could be the organization of recurring community-wide challenges, similar to established competitions in other fields (e.g., CASP[Moult (2005)]). These challenges—ideally coordinated by major research consortia or national labs—can serve as shared reference points, drive innovation in evaluation design.
4.4.1.1 Standardization Efforts
One persistent challenge in evaluating GPMs is the lack of common standards—whether in benchmark design, metric selection, or reporting protocols. This fragmentation makes it challenging to compare results or ensure reproducibility. While some degree of standardization can support transparency and cumulative progress, rigid frameworks risk constraining innovation and may conflict with the need in scientific discovery for more open-ended, adaptive evaluations.
A more feasible path may lie in promoting transparent documentation of evaluation choices and developing meta-evaluation tools that assess the validity, coverage, and robustness of different approaches. Emerging frameworks such as item response theory (IRT) offer promising directions. [Schilling-Wilhelmi, Alampara, and Jablonka (2025)]